|
Greetings! I am a research scientist at Ascent Robotics Inc, doing R&D on self-driving car technology. I was a project researcher at the National Institute of Informatics, Tokyo, Japan, where I conducted research on applications of deep learning in the medical domain with Prof. Shin'ichi Satoh at Satoh Lab, and in the Vision and Language domain with Prof. Yusuke Miyao at Miyao Lab. I received my PhD degree in Informatics from SOKENDAI (The Graduate University for Advanced Studies) in Oct 2015, under the guidance of Prof. Shin'ichi Satoh and Prof. Duy-Dinh Le, and was funded by the National Institute of Informatics. Prior to that, I obtained my master's and bachelor's degrees at the University of Science - Vietnam National University Ho Chi Minh City. Email / CV / DBLP / Google Scholar / LinkedIn |

|
|
I am interested in applications of machine learning and data science in computer vision and natural language processing. The focus of my research is mainly on the intersection of these areas, with several interesting applications such as video event detection and recounting, image/video description generation and image/video question answering. |
|
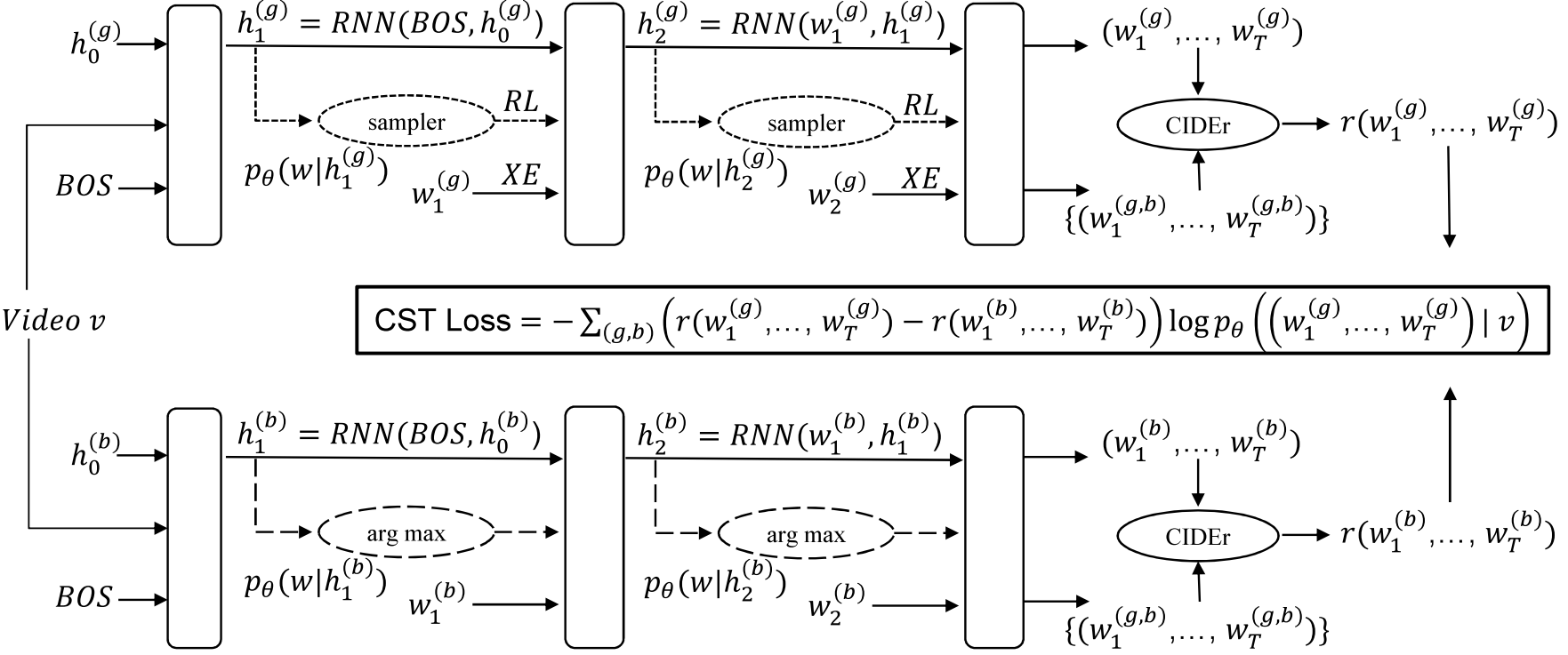
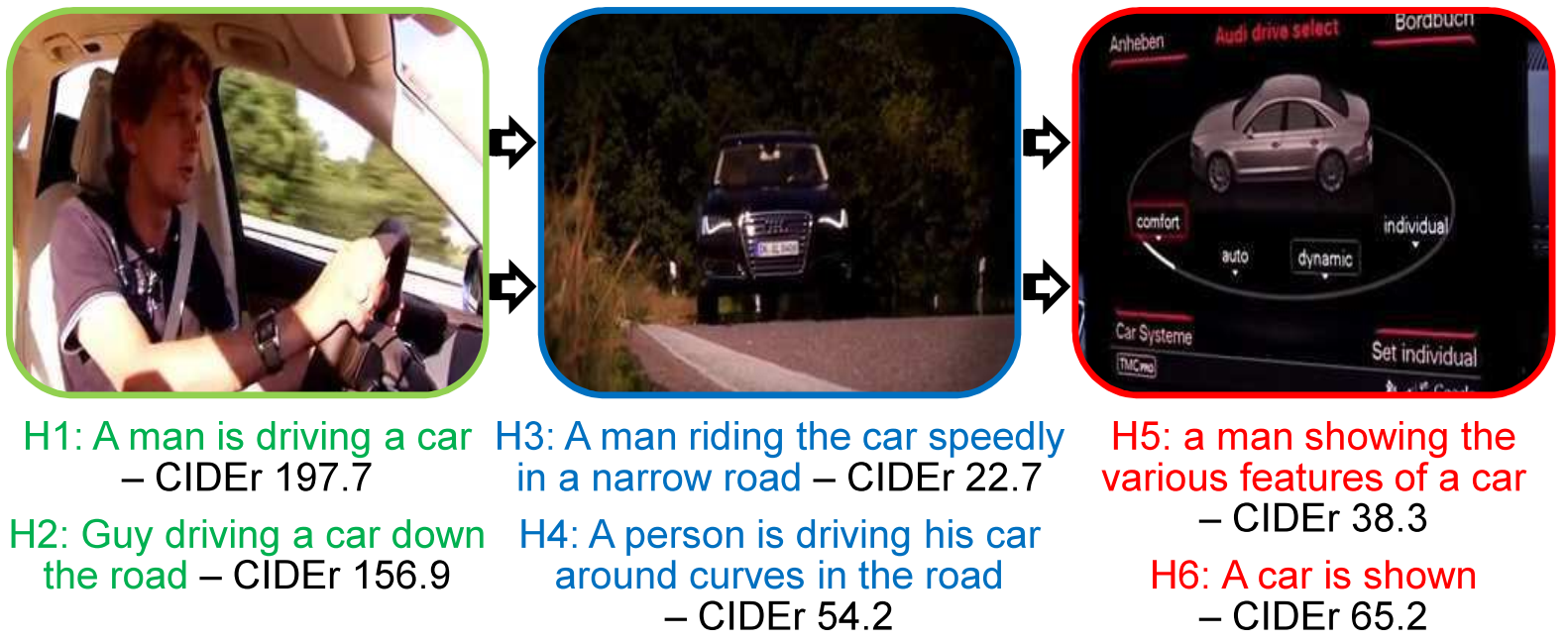
Sang Phan, Gustav Eje Henter, Yusuke Miyao, Shin'ichi Satoh arXiv Preprint, 2017, [Code] We propose a Consensus-based Sequence Training (CST) scheme to generate video captions. First, CST performs an RLlike pre-training, but with captions from the training data replacing model samples. Second, CST applies REINFORCE for fine-tuning using the consensus (average reward) among training captions as the baseline estimator. The two stages of CST allow objective mismatch and exposure bias to be assessed separately, and together establish a new state-of-the-art on the task. |
|
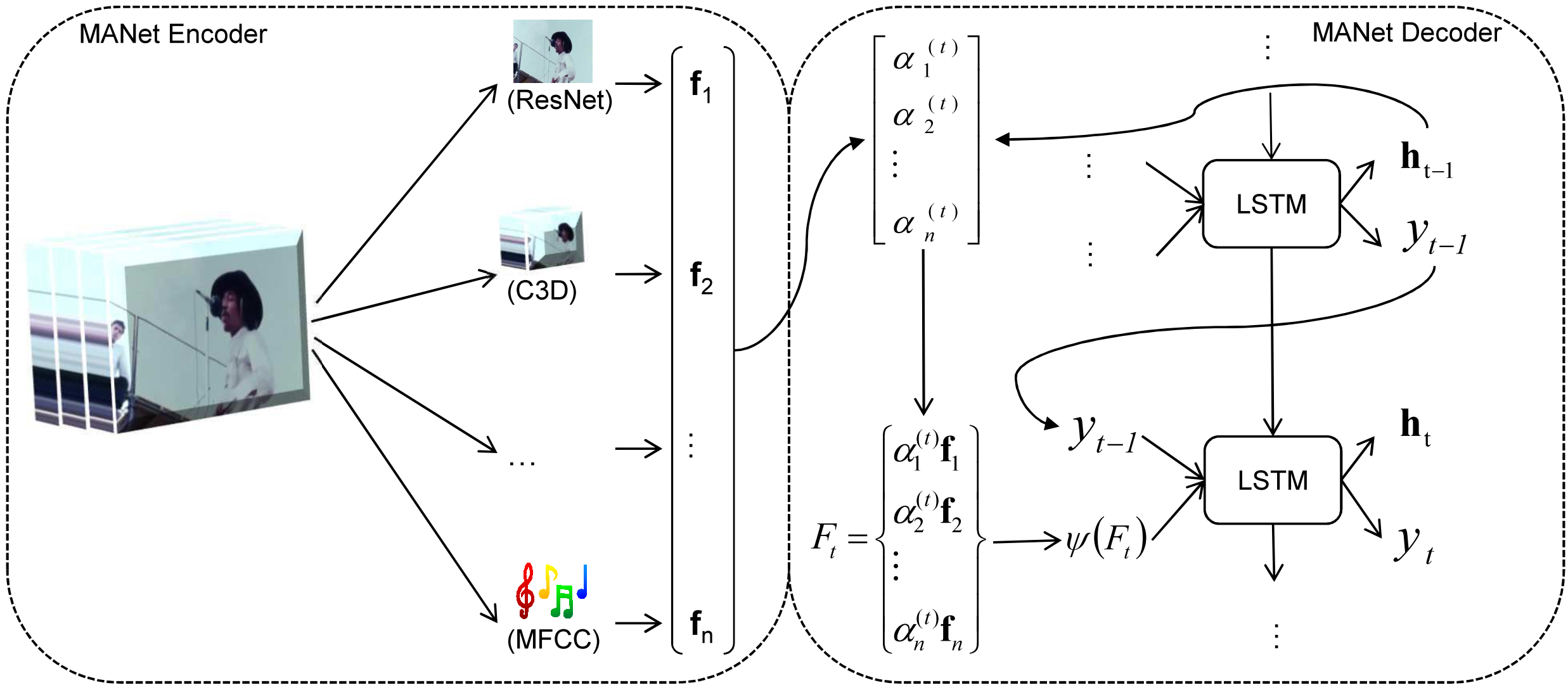
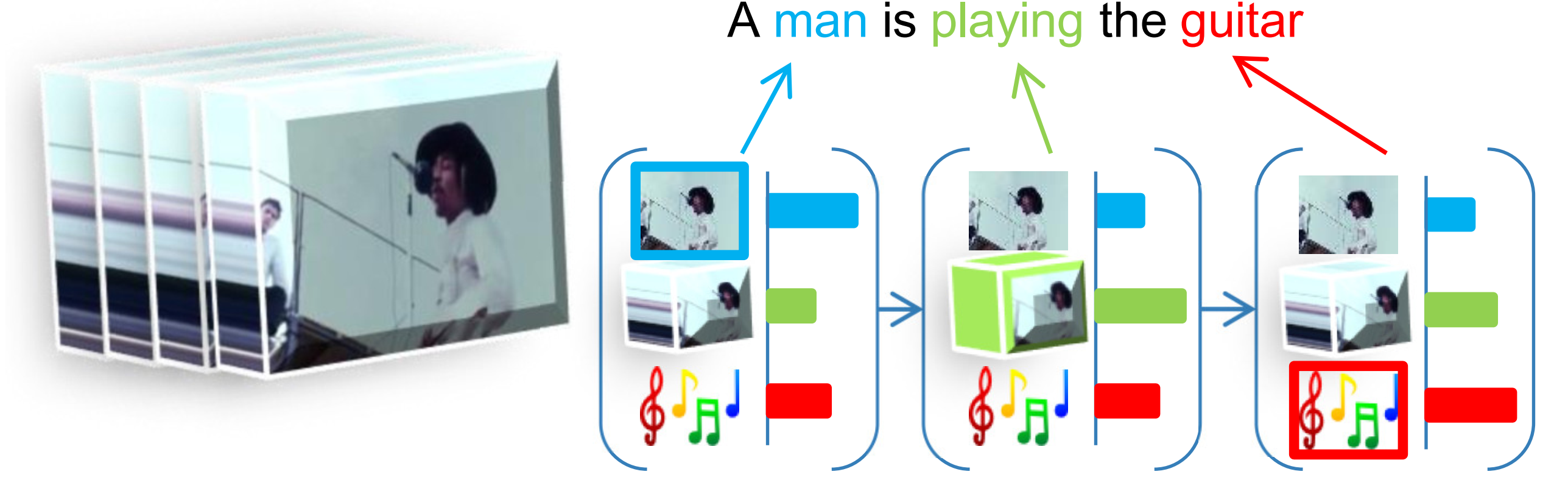
We propose a Modal Attention Network (MANet) to learn dynamic weighting combinations of multimodal features (audio, image, motion, and text) for video captioning. Our MANet extends the standard encoder-decoder network by adapting the attention mechanism to video modalities. |
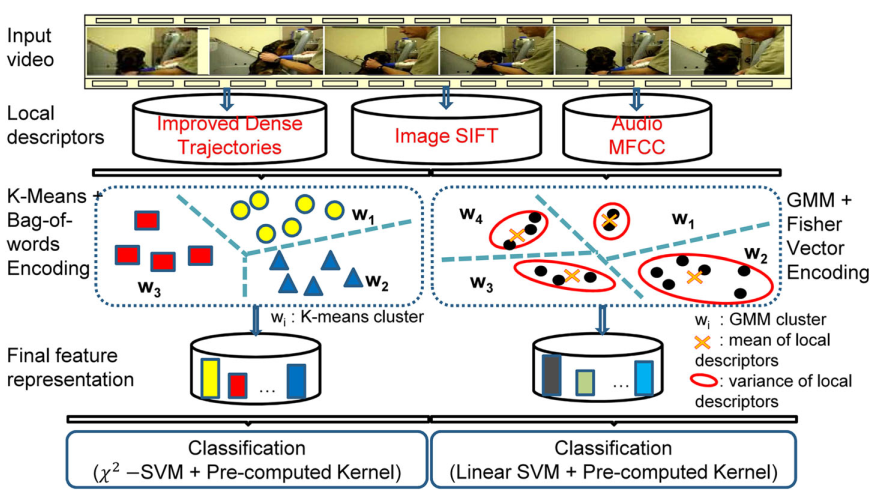 |
We evaluated the performance of various features in violent scenes detection. The evaluated features included global and local image features, motion features, audio features, VSD concept features, and deep learning features. We also compared two popular encoding strategies: Bag-of-Words and Fisher vector. |
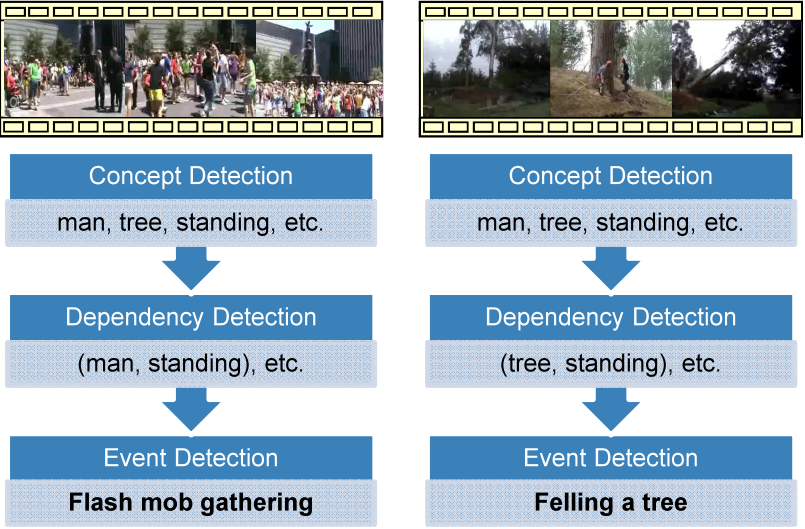 |
We propose a new approach to obtain the relationship between concepts by exploiting the syntactic dependencies between words in the image captions. |
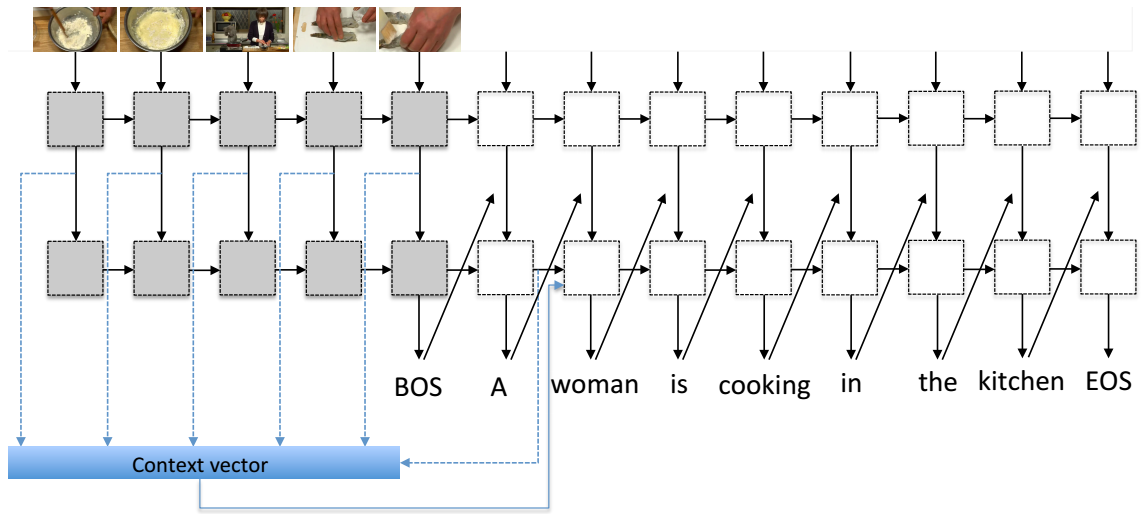 |
We combine sequence to sequence approach with temporal attention mechanism for video captioning. |
 |
We propose to use Event-driven Multiple Instance Learning (EDMIL) to learn the key evidences for event detection. The key evidences are obtained by matching its detected concepts against the evidential description of that event. |
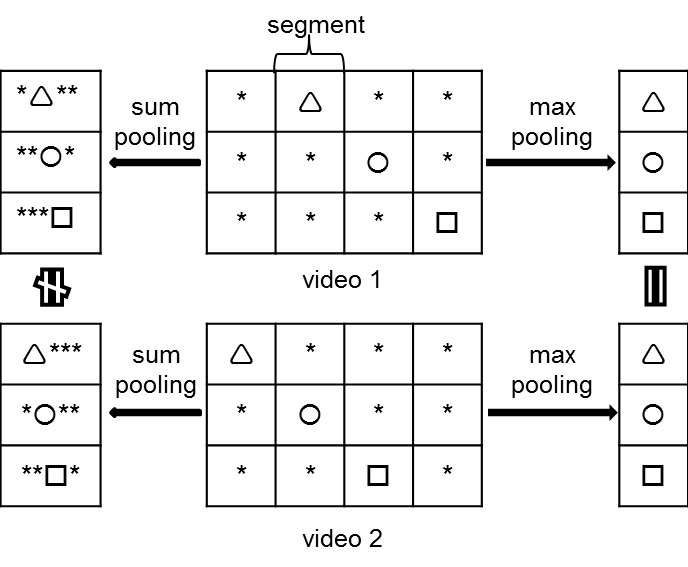 |
We leverage the layered structure of video to propose a new pooling method, named sum-max video pooling, to combine the advantages of sum pooling and max pooling for video event detection. |
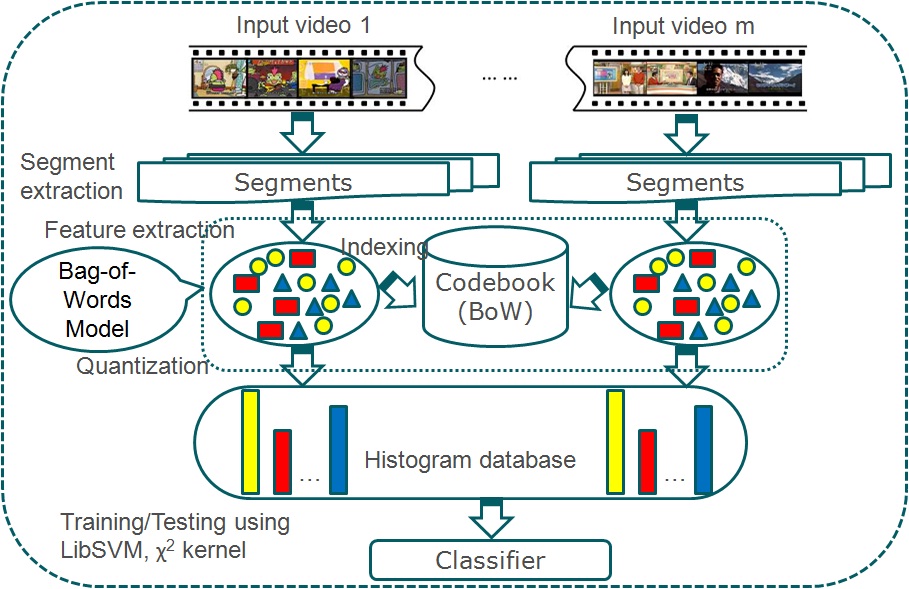 |
We propose to use a segment-based approach for video representation. Basically, original videos are divided into segments for feature extraction and classification, while still keeping the evaluation at the video level. Experimental results on the TRECVID Multimedia Event Detection 2010 dataset proved the effectiveness of our approach. |
|
|
|
|